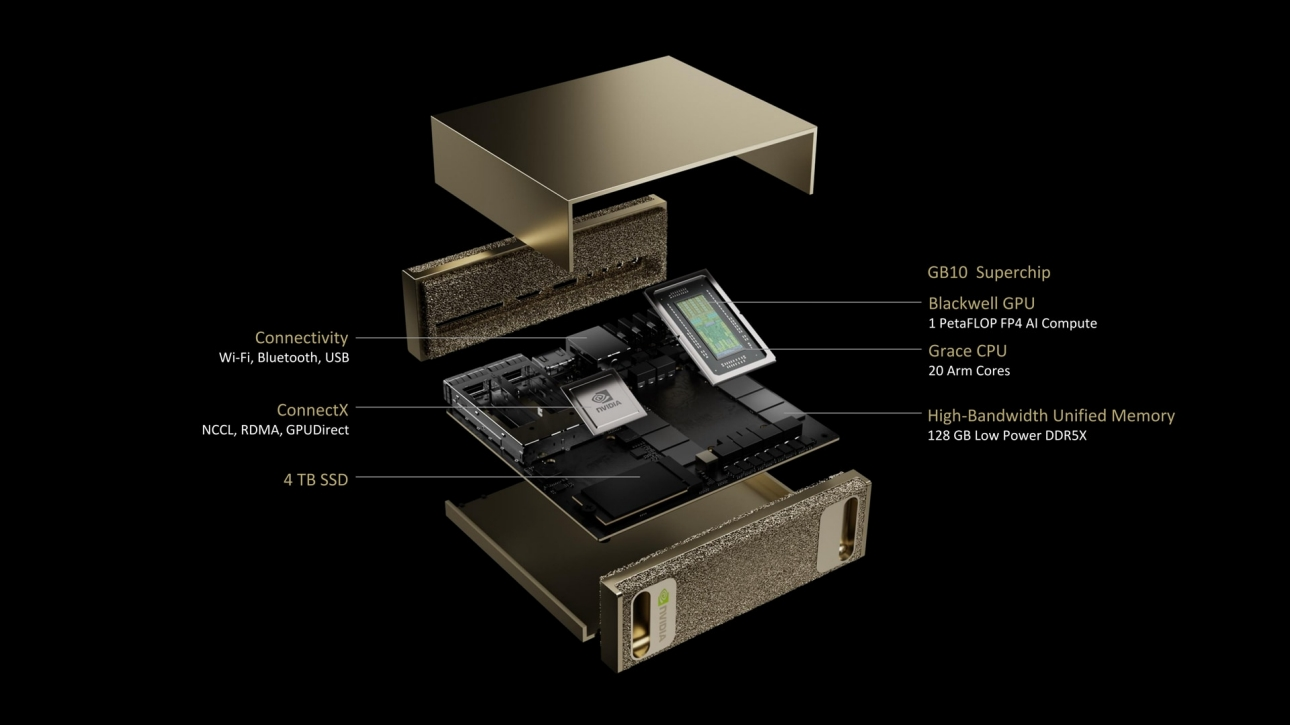
Superchip NVIDIA GB10
Hasta 1 petaFLOP de rendimiento de IA con precisión FP4. Arquitectura Grace Blackwell diseñada para la máxima eficiencia.
Memoria Unificada
128 GB de memoria de sistema unificada coherente. Permite ejecutar modelos de hasta 200.000 millones de parámetros localmente.
Interconexión ConnectX
Redes de alto rendimiento ConnectX-7 que permiten el stacking de dos sistemas para escalar hasta 405.000 millones de parámetros.
Inferencia y Paralelismo
Rendimiento excelente en tareas de inferencia distribuida. Optimizado para paralelismo de tensor y pipeline mediante NVLink y RDMA.
Guías Técnicas de Despliegue
Selecciona el modo de operación para acceder a la documentación específica.